The 16GB Laptop Revolution: Can Gemma 4 12B Replace Enterprise Cloud Agents?
Google DeepMind's new Gemma 4 12B model ditches traditional encoders for a unified architecture, promising native multimodal reasoning on consumer hardware. This shift challenges the status quo of cloud-dependent AI agents and raises critical questions about the future of sovereign, local enterprise computing.

Photo by Google DeepMind on Pexels
The 16GB Laptop Revolution: Can Gemma 4 12B Replace Enterprise Cloud Agents?
Google DeepMind may have just fired the opening shot in the next battle for enterprise AI. With the release of Gemma 4 12B, the company is not merely shrinking a multimodal model to fit on consumer hardware. It is challenging a core assumption that has defined the generative AI era: that powerful AI agents must live in the cloud.
Consider a legal firm handling thousands of confidential contracts. Until now, running multimodal AI on those documents often meant uploading sensitive files to external servers, introducing compliance concerns, latency, and recurring API costs. Gemma 4 12B changes that equation. The model can process text, images, audio, and video locally on systems equipped with just 16GB of VRAM or unified memory, allowing enterprises to keep workloads entirely within their own infrastructure.
Google's Architectural Gamble
The most significant story is not the model size. It is the architecture.
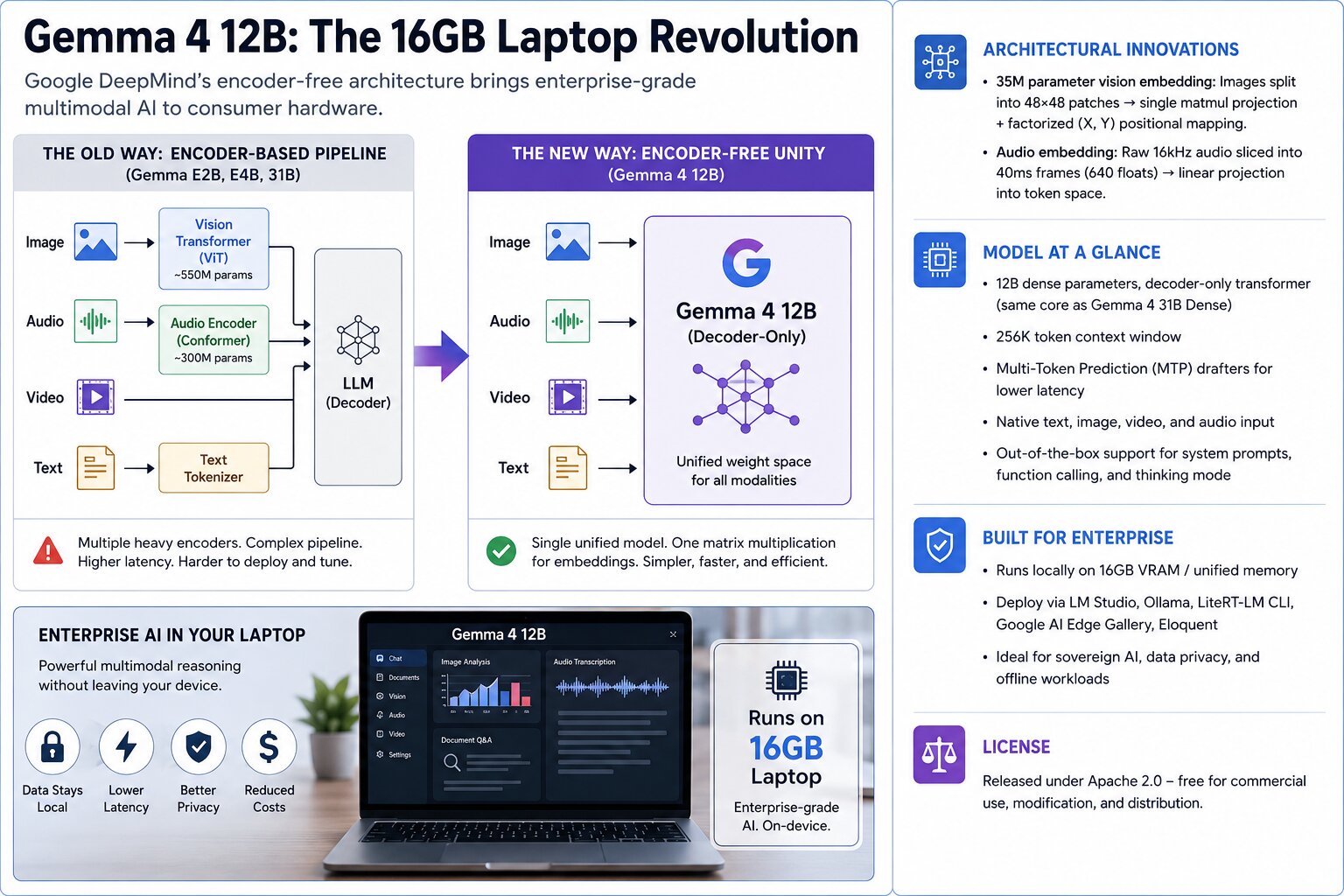
Gemma 4 12B is a 12-billion-parameter dense decoder-only transformer that shares the same core decoder design as Google's larger Gemma 4 31B Dense model. Unlike previous Gemma variants—including E2B, E4B, and 31B—which relied on separate neural networks for vision and audio processing, the new model removes those heavyweight encoders entirely.
Traditional multimodal systems typically route images through a Vision Transformer and audio through a dedicated encoder such as a Conformer before handing information to the language model. Gemma 4 12B eliminates that chain.
Instead, Google feeds all modalities directly into a unified LLM backbone.
For vision tasks, the company replaces a 550-million-parameter vision encoder with a lightweight 35-million-parameter embedding module. Images are divided into 48×48-pixel patches and projected into the model's hidden dimension through a single matrix multiplication. Spatial relationships are preserved through learned X and Y coordinate mappings.
Audio follows a similar philosophy. Rather than passing sound through a dedicated 300-million-parameter audio encoder, Gemma 4 12B slices raw 16 kHz audio into 40-millisecond frames and projects them directly into the model's token space.
The result is a radically simplified architecture.
Why Enterprises Should Pay Attention
The technical simplification carries major operational consequences.
Most multimodal AI deployments require organizations to maintain multiple model components, each demanding separate optimization, tuning, and infrastructure support. Gemma 4 12B collapses those layers into a single system.
Because text, image, and audio inputs share the same weight space, developers can fine-tune the model through a single training process. Techniques such as LoRA automatically update all modalities simultaneously rather than requiring separate adaptation pipelines.
For enterprises, that means lower deployment complexity and faster iteration cycles.
The model also ships with a 256K token context window, large enough to analyze extensive legal archives, research repositories, lengthy transcripts, or multi-hour audio recordings in a single session. Combined with Multi-Token Prediction (MTP) drafters, Google aims to reduce inference latency while maintaining local execution.
The Rise of Sovereign AI
The timing matters.
Across finance, healthcare, government, and legal sectors, data sovereignty has become a boardroom priority. Organizations increasingly want AI systems that operate within their own environments rather than sending information to external providers.
Gemma 4 12B fits directly into that trend.
The model supports deployment through LM Studio, Ollama, LiteRT-LM CLI, Google AI Edge Gallery, and Eloquent, giving organizations multiple paths to local inference. Google's new LiteRT-LM serving capabilities even provide OpenAI-compatible endpoints, making migration easier for developers already building agentic workflows.
This local-first approach also reduces dependency on recurring cloud inference costs, a growing concern as enterprise AI usage scales.
Apache 2.0 Opens the Door
Licensing could prove just as important as architecture.
Google released Gemma 4 12B under the Apache 2.0 license, providing enterprises with broad rights to modify, distribute, and integrate the model into commercial products. Legal teams that once hesitated around restrictive AI licenses now have significantly clearer terms.
Yet questions remain.
The release offers open weights, not full reproducibility. Enterprises still depend on Google's training decisions, datasets, and model development process. Critics argue that true transparency remains elusive despite the permissive licensing model.
Can It Really Challenge Cloud Agents?
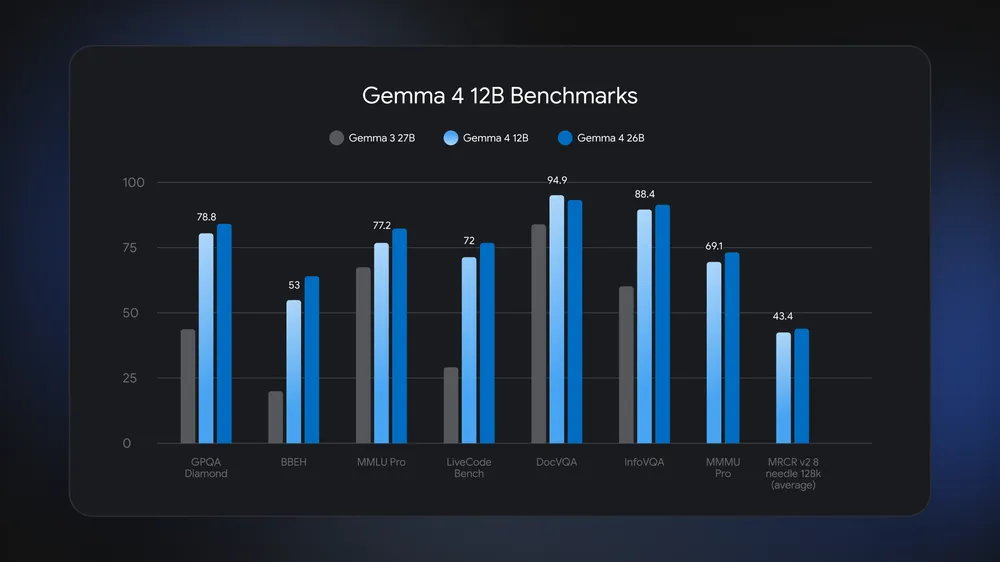
Google claims Gemma 4 12B delivers performance approaching its larger 26B Mixture-of-Experts model while consuming less than half the memory footprint. The model also introduces native audio support to the mid-sized Gemma lineup for the first time, alongside built-in function calling, system prompts, and configurable reasoning modes designed for agentic workflows.
Those capabilities make it a serious candidate for local AI agents.
The remaining question centers on specialization. Unified architectures offer elegance and efficiency, but highly optimized vision or audio systems may still outperform a general-purpose model in niche workloads.
Even so, Gemma 4 12B signals a broader shift. The industry spent the last three years moving intelligence into massive cloud clusters. Google now suggests a different future—one where enterprise-grade multimodal agents run directly on the devices sitting on employees' desks.
If that vision holds, the most important AI infrastructure of the next decade may not be a hyperscale data center. It may be a 16GB laptop.