The 'Price War' is Official: Why DeepSeek’s Permanent Cut Strains Western AI Margins
DeepSeek has officially locked in its 75% API discount, signaling a structural pivot that forces OpenAI and Anthropic to reconcile their premium pricing. This move transforms AI inference from a high-margin growth engine into a volatile battlefield.

Photo by Adriana Beckova on Pexels
The AI Price War Is Official: Why DeepSeek’s Permanent Cut Is Reshaping Global AI Economics
DeepSeek has officially locked in its 75% API discount, signaling a structural pivot that forces Western AI leaders like OpenAI, Anthropic, and Google to reconcile their premium pricing models with a rapidly commoditizing inference market.
What began as a temporary launch promotion has now become something far more disruptive: a permanent restructuring of AI infrastructure economics.
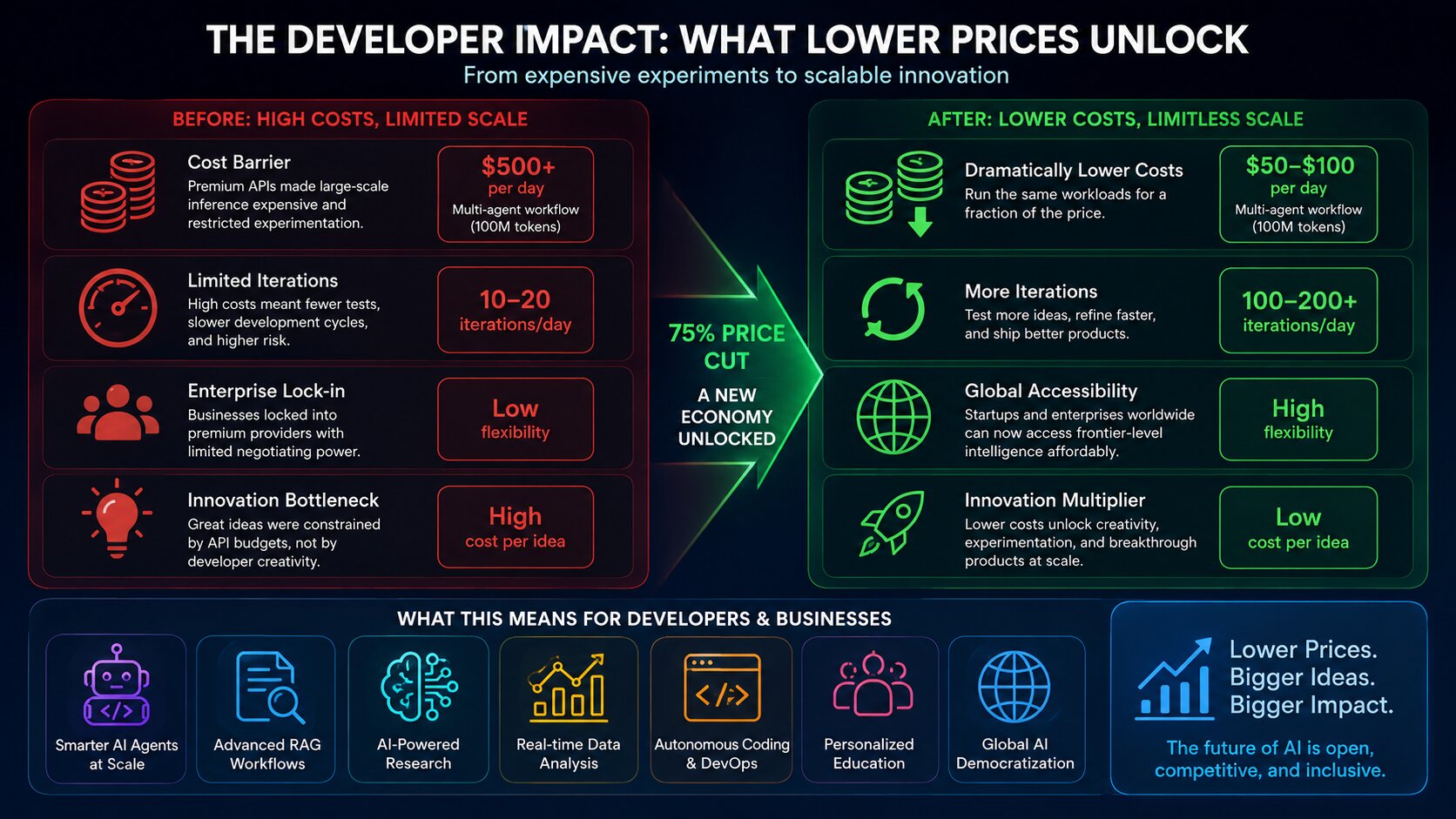
The End of “Growth Hack” Pricing
Over the weekend, DeepSeek formally confirmed that the promotional pricing on its flagship V4-Pro API will become the permanent baseline beginning June 1, 2026.
Instead of reverting to standard enterprise pricing after May 31, the company permanently reduced rates from:
- ¥24 → ¥6 per million output tokens
- ¥12 → ¥3 per million input tokens
At current exchange rates, that translates to approximately:
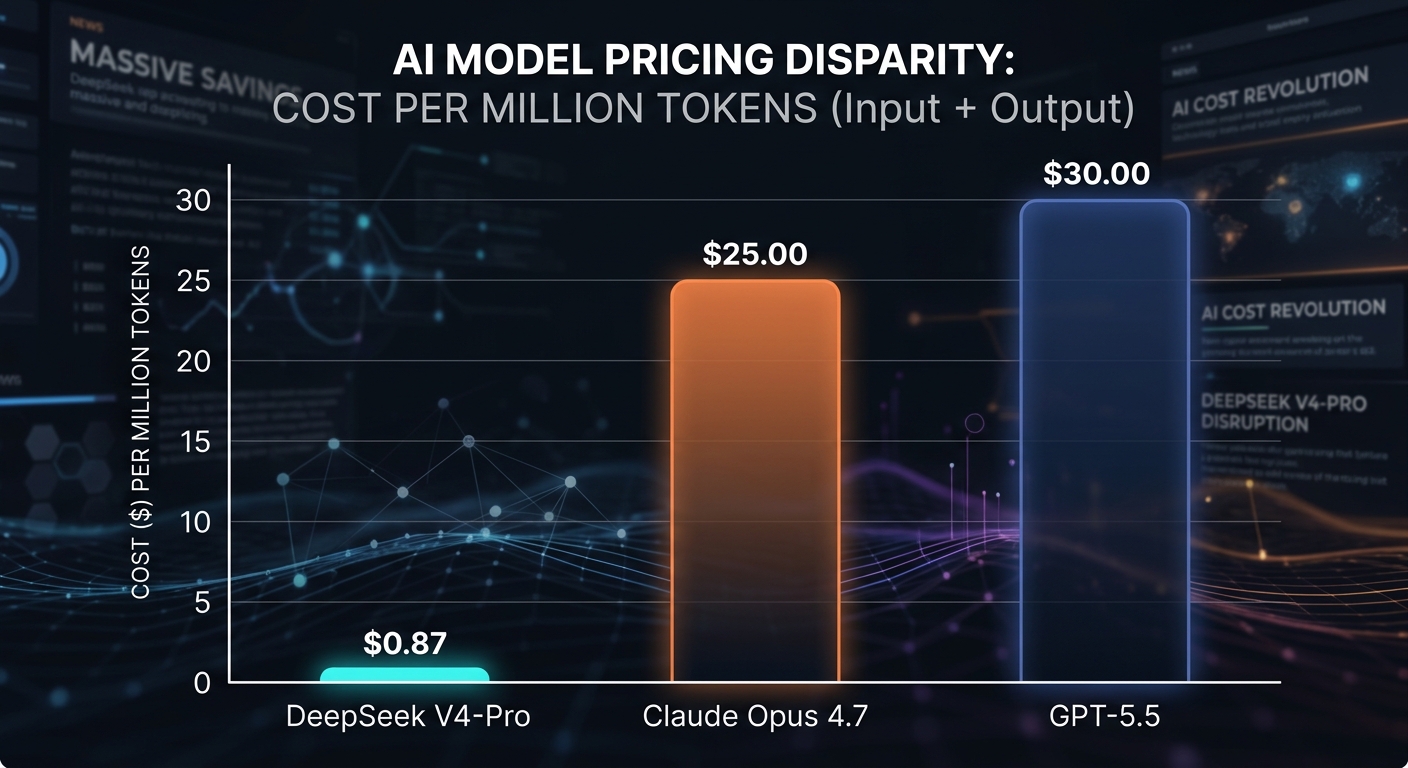
- $0.435 per million input tokens
- $0.87 per million output tokens
The implications are enormous. This is no longer a customer-acquisition strategy. It is a declaration that high-end reasoning models can operate profitably at radically lower margins.
For years, Western AI firms relied on premium API pricing to subsidize frontier model training, massive GPU clusters, and enterprise expansion. DeepSeek’s move directly attacks that economic assumption.
“DeepSeek just confirmed that their 75% promo discount for the V4-Pro API is actually becoming the permanent price. It's right there on their official pricing page now.”
— u/tech_analyst_24, r/Investing
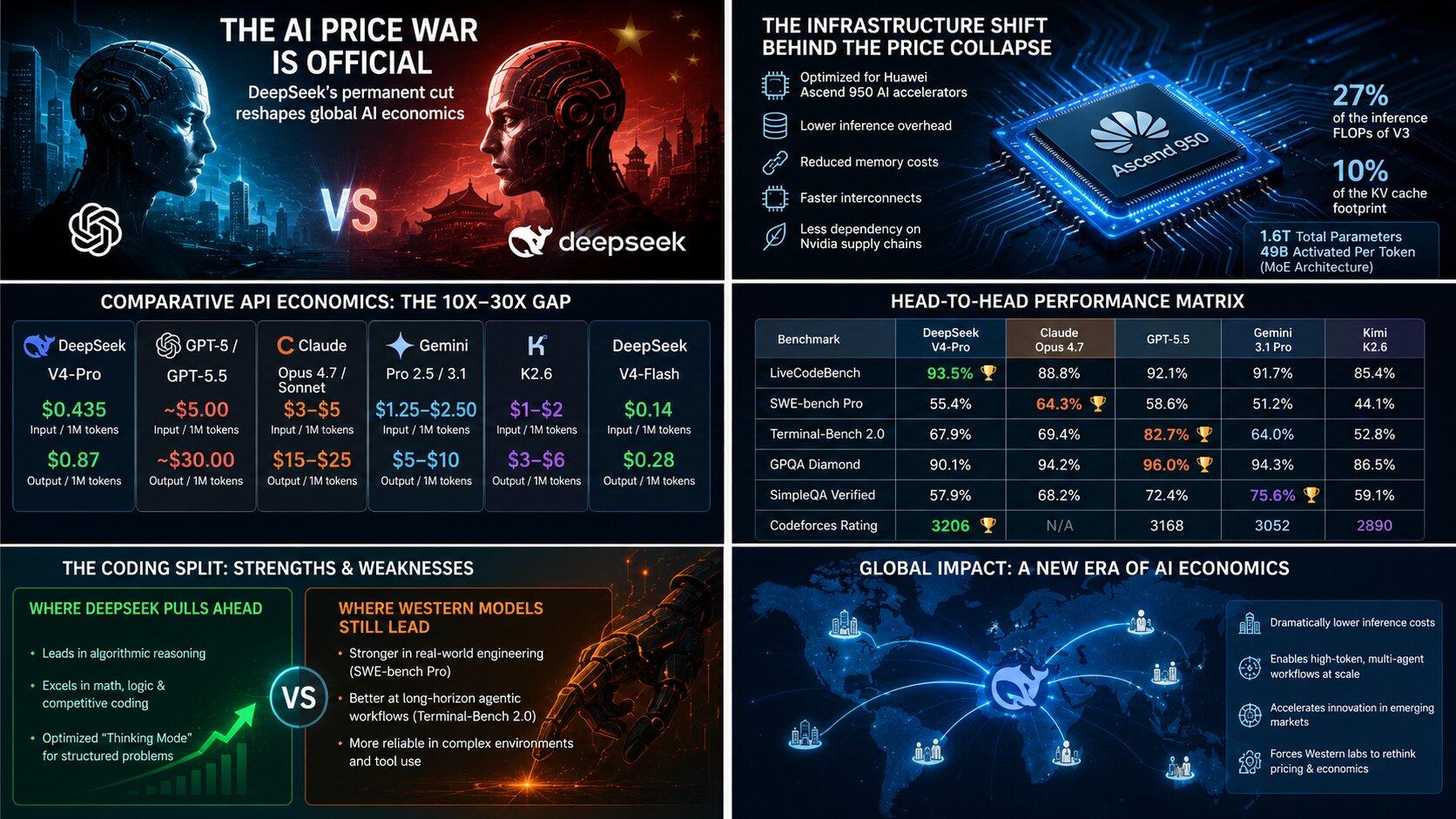
The Infrastructure Shift Behind the Collapse in Pricing
The story is not simply about lower prices — it is about how DeepSeek achieved them.
Rather than remaining dependent on constrained Nvidia supply chains, DeepSeek aggressively optimized around a localized compute ecosystem powered by Huawei Ascend 950 AI accelerators and tightly integrated software stacks.
This dramatically lowers:
- inference overhead
- memory costs
- interconnect bottlenecks
- GPU procurement exposure
The result is a structural efficiency advantage rather than a temporary subsidy.
At the architectural level, DeepSeek V4-Pro runs on a 1.6-trillion-parameter Mixture of Experts (MoE) framework, but critically activates only 49 billion parameters per token during inference.
According to internal technical audits, V4-Pro requires:
- only 27% of the inference FLOPs of the previous V3 generation
- roughly 10% of the KV cache footprint
That means DeepSeek is not brute-forcing intelligence with larger compute budgets. It is extracting more usable reasoning per watt and per token than most competitors.
Independent evaluations from the Center for AI Safety and Infrastructure (CAISI) suggest DeepSeek achieves capability levels close to Western frontier systems released approximately 6–8 months earlier, while operating at dramatically lower cost structures.
"“Everyone who understood the paper saw this coming. It’s an astonishingly efficient model.”
— u/ai_dev_daily, r/ArtificialInteligence
Comparative API Economics: The 10x–30x Gap
The pricing disparity is now impossible for the market to ignore.
| Model | Input Price (1M Tokens) | Output Price (1M Tokens) | Notes |
|---|---|---|---|
| DeepSeek V4-Pro | $0.435 | $0.87 | Cheapest flagship reasoning model |
| DeepSeek V4-Flash | $0.14 | $0.28 | Ultra-high-volume tier |
| GPT-5 / GPT-5.5 | ~$5.00 | ~$30.00 | Premium frontier pricing |
| Claude Opus 4.7 / Sonnet | $3–$5 | $15–$25 | Enterprise coding benchmark |
| Gemini Pro 2.5 / 3.1 | $1.25–$2.50 | $5–$10 | Strong multimodal stack |
| Kimi K2.6 | $1–$2 | $3–$6 | Domestic Chinese competitor |
The economic conclusion is stark:
DeepSeek V4-Pro delivers roughly 90–95% of frontier capability at approximately 3–10% of the cost of leading Western APIs.
For enterprise-scale agentic systems — especially workflows consuming tens or hundreds of millions of reasoning tokens daily — the savings become transformative.
A multi-agent orchestration pipeline that previously cost hundreds of dollars per day using premium Western APIs can now run for a fraction of that amount.
For cost-sensitive markets like India, Southeast Asia, Latin America, and parts of Eastern Europe, the economics become overwhelmingly compelling.
Benchmark Reality: DeepSeek Is No Longer “Good for the Price”
The most important development is that DeepSeek is no longer merely a budget alternative.
On several hard reasoning benchmarks, it is now operating at or near frontier level.
Head-to-Head Performance Matrix
| Benchmark | DeepSeek V4-Pro | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro | Kimi K2.6 |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5% 🥇 | 88.8% | 92.1% | 91.7% | 85.4% |
| SWE-bench Pro | 55.4% | 64.3% 🥇 | 58.6% | 51.2% | 44.1% |
| Terminal-Bench 2.0 | 67.9% | 69.4% | 82.7% 🥇 | 64.0% | 52.8% |
| GPQA Diamond | 90.1% | 94.2% | 96.0% 🥇 | 94.3% | 86.5% |
| SimpleQA Verified | 57.9% | 68.2% | 72.4% | 75.6% 🥇 | 59.1% |
| Codeforces Rating | 3206 🥇 | N/A | 3168 | 3052 | 2890 |
Where DeepSeek Pulls Ahead
The most disruptive part of DeepSeek’s rise is not merely the pricing advantage — it is how narrow the capability gap has become in the areas developers care about most.
On pure algorithmic reasoning benchmarks, DeepSeek V4-Pro is no longer viewed as a “budget alternative.” In several categories, it outright leads the market. The model currently tops major evaluations like LiveCodeBench and competitive Codeforces-style testing, consistently outperforming Western rivals in raw mathematical reasoning and structured coding tasks.
That strength has made V4-Pro especially attractive for engineering-heavy workloads. Developers building autonomous coding agents, quantitative finance tools, theorem-style reasoning systems, and competitive programming pipelines are increasingly prioritizing DeepSeek because its reasoning capabilities rival frontier Western models at a fraction of the operating cost.
The explanation appears rooted in DeepSeek’s aggressively optimized “Thinking Mode,” which allocates compute toward symbolic reasoning and tightly constrained logic environments. In practice, the model excels when problems are deterministic, structured, and mathematically intensive.
Where Western Models Still Maintain an Edge
The benchmarks also reveal a critical divide.
While DeepSeek dominates isolated reasoning tasks, Western models continue to hold a meaningful advantage in long-horizon autonomous workflows — the category increasingly defining enterprise AI deployment.
On SWE-bench Pro, which measures a model’s ability to understand and modify large real-world software repositories, Anthropic’s Claude Opus 4.7 maintains a clear lead. Analysts attribute that advantage to stronger repository-level planning, deeper dependency awareness, and more sophisticated self-verification loops during complex code modifications.
Meanwhile, OpenAI remains dominant in true agentic orchestration. On Terminal-Bench 2.0 — a benchmark designed to evaluate how effectively models manage shell environments, tools, file systems, and extended autonomous tasks — GPT-5.5 significantly outperforms DeepSeek.
That distinction matters because the next wave of enterprise AI is increasingly centered around persistent autonomous systems rather than one-shot prompting. Real-world deployments now require models capable of coordinating tools, managing memory across sessions, executing shell commands safely, and recovering from failure states during multi-hour workflows.
This is where DeepSeek still shows weakness. Despite its remarkable reasoning efficiency, researchers continue to observe “drift” during extended task execution, particularly in environments requiring long-duration planning and orchestration.
The Hallucination Problem Has Not Disappeared
The company’s largest vulnerability, however, may be factual reliability.
On SimpleQA Verified — a benchmark focused on factual precision and hallucination resistance — DeepSeek trails both Google’s Gemini and OpenAI’s GPT systems by a significant margin. Researchers believe this reflects a deliberate architectural tradeoff: DeepSeek appears to prioritize reasoning efficiency over maintaining large-scale world knowledge retrieval systems.
For coding, mathematics, and structured logic tasks, that compromise is often acceptable. But for industries where factual accuracy is mission-critical — including legal workflows, healthcare summarization, enterprise knowledge systems, and compliance-heavy customer support — Western models continue to retain a meaningful edge.
DeepSeek’s Growing Dominance Inside China
At the same time, DeepSeek’s dominance is becoming increasingly visible inside China itself.
Within the domestic AI ecosystem, the company has rapidly emerged as a direct threat to Moonshot AI and its Kimi platform. While Kimi remains popular for conversational memory and long-document interactions, DeepSeek now leads across most high-value reasoning benchmarks, including mathematics, coding, and logic-intensive tasks — while simultaneously undercutting competitors on cost.
That combination creates a powerful structural moat.
The Pressure on Western AI Economics
And it is precisely this moat that now threatens the economics of Western AI labs.
For companies like OpenAI, Anthropic, and Google, premium API pricing is not simply a monetization strategy — it is the financial engine funding frontier model training, GPU procurement, enterprise expansion, and safety research.
DeepSeek’s permanent pricing shift fundamentally destabilizes that equation.
Chinese labs benefit from lower infrastructure costs, localized hardware ecosystems, thinner operating margins, and increasingly mature domestic AI supply chains. Western firms, by contrast, remain heavily exposed to expensive Nvidia-centered compute stacks and investor expectations built around premium-margin software economics.
That creates an asymmetric pricing war.
If Western labs attempt to match DeepSeek’s pricing directly, they risk severe margin compression. But if they refuse, developers may increasingly split workloads between providers — routing commodity reasoning tasks to DeepSeek while reserving premium Western APIs only for multimodal systems, enterprise compliance, and advanced autonomous agents.
For Silicon Valley, that possibility represents a dangerous market bifurcation.
Why Developers Are Paying Attention
For developers, however, the shift is transformative.
The collapse in inference costs means that high-token, multi-agent workflows that were previously economically unrealistic are suddenly deployable at scale. Startups building legal copilots, autonomous research systems, fintech analysis engines, tutoring platforms, and enterprise automation pipelines are no longer constrained primarily by API pricing.
Instead, the competitive bottleneck is shifting toward orchestration quality, reliability, and product execution.
That may ultimately be the most important consequence of DeepSeek’s move.
The Bottom Line
DeepSeek is not necessarily replacing the absolute frontier of Western AI capability. Models like GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro still lead in multimodal integration, enterprise reliability, factual precision, and long-horizon autonomy.
But DeepSeek may not need to surpass them outright to fundamentally reshape the market.
By delivering near-frontier reasoning performance at a tiny fraction of the cost, the company has transformed high-end inference from a premium enterprise luxury into an increasingly commoditized infrastructure layer.
And for the first time since the generative AI boom began, Western AI companies are being forced to defend not only their technological leadership — but the economic foundations underneath it.